Azul and LLMs
13 Jan 2026
Azul1 to Study LLM Capability & Planning
Azul is an abstract strategy game where you draft colored tiles to fill rows on your board and score points. It’s become a household favorite — simple to learn, and it provides nice balance of creativity, planning, reasoning, and ruthlessness.
That makes it a useful sandbox for LLMs. The rules fit in a prompt. The game is popular enough that models have likely seen it in training, but it’s not hugely popular. Being good requires good planning and paying attention to what your opponent is doing.
Capability
I ran a few hundred games across different model matchups and computed Elo ratings. The headline: MCTS (Monte Carlo Tree Search with a greedy rollout policy) still beats all the LLMs. Not surprising, but I was surprised that some models are not so far from the MCTS baseline.
| Model | Elo | Games | W | L | D | Win Rate | 95% CI |
|---|---|---|---|---|---|---|---|
| mcts-greedy | 221.7 | 64 | 49 | 14 | 1 | 77.3% | 128.9–334.3 |
| google/gemini-3-flash-preview | 111.5 | 83 | 52 | 28 | 3 | 64.5% | 46.4–187.8 |
| openai/gpt-5-mini | 19.1 | 83 | 39 | 39 | 5 | 50.0% | -58.9–105.3 |
| x-ai/grok-4.1-fast | -16.6 | 64 | 24 | 36 | 4 | 40.6% | -100.6–70.8 |
| openai/gpt-oss-120b | -124.0 | 82 | 19 | 60 | 3 | 25.0% | -197.6–-38.3 |
| anthropic/claude-haiku-4.5 | -211.6 | 10 | 2 | 8 | 0 | 20.0% | -447.9–-55.8 |
Gemini 3 Flash is the best LLM here, winning about two-thirds of its games. GPT-5-mini sits right at 50%. The confidence intervals are wide (small sample sizes), so I wouldn’t read too much into the exact rankings — but it’s clear the models can play the game at a level that makes comparisons interesting.
Do They Think About Their Opponent?
I asked each model to explain its rationale when it makes a move. As a first pass, I just did keyword matching: how often does each model mention things like “opponent,” “block,” “deny,” or “steal”?
| Model | Turns | Opponent-Aware Mentions | Rate (95% CI) |
|---|---|---|---|
| openai/gpt-5-mini | 2415 | 974 | 40.33% (38.39–42.30) |
| x-ai/grok-4.1-fast | 1913 | 650 | 33.98% (31.89–36.13) |
| google/gemini-3-flash-preview | 2390 | 683 | 28.58% (26.80–30.42) |
| openai/gpt-oss-120b | 2340 | 307 | 13.12% (11.81–14.55) |
| anthropic/claude-haiku-4.5 | 261 | 7 | 2.68% (1.31–5.43) |
GPT-5-mini talks about opponents a lot — 40% of its move explanations mention them. Gemini does it less (28%). And Claude Haiku barely mentions opponents at all, though the sample size there is tiny (Haiku’s expensive and sometimes overthinks…).
But interestingly: talking about opponents more doesn’t mean winning more. Gemini outperforms GPT-5-mini despite discussing opponents less frequently. Maybe Gemini is just better at understanding the game — state tracking, avoiding penalties, efficient tile placement — and doesn’t need to narrate its blocking plays. Or maybe GPT-5-mini is overindexing on opponent awareness at the cost of its own board optimization. Big emphasis on super preliminary because all of this is very lexical, not grounded in any causal analysis.
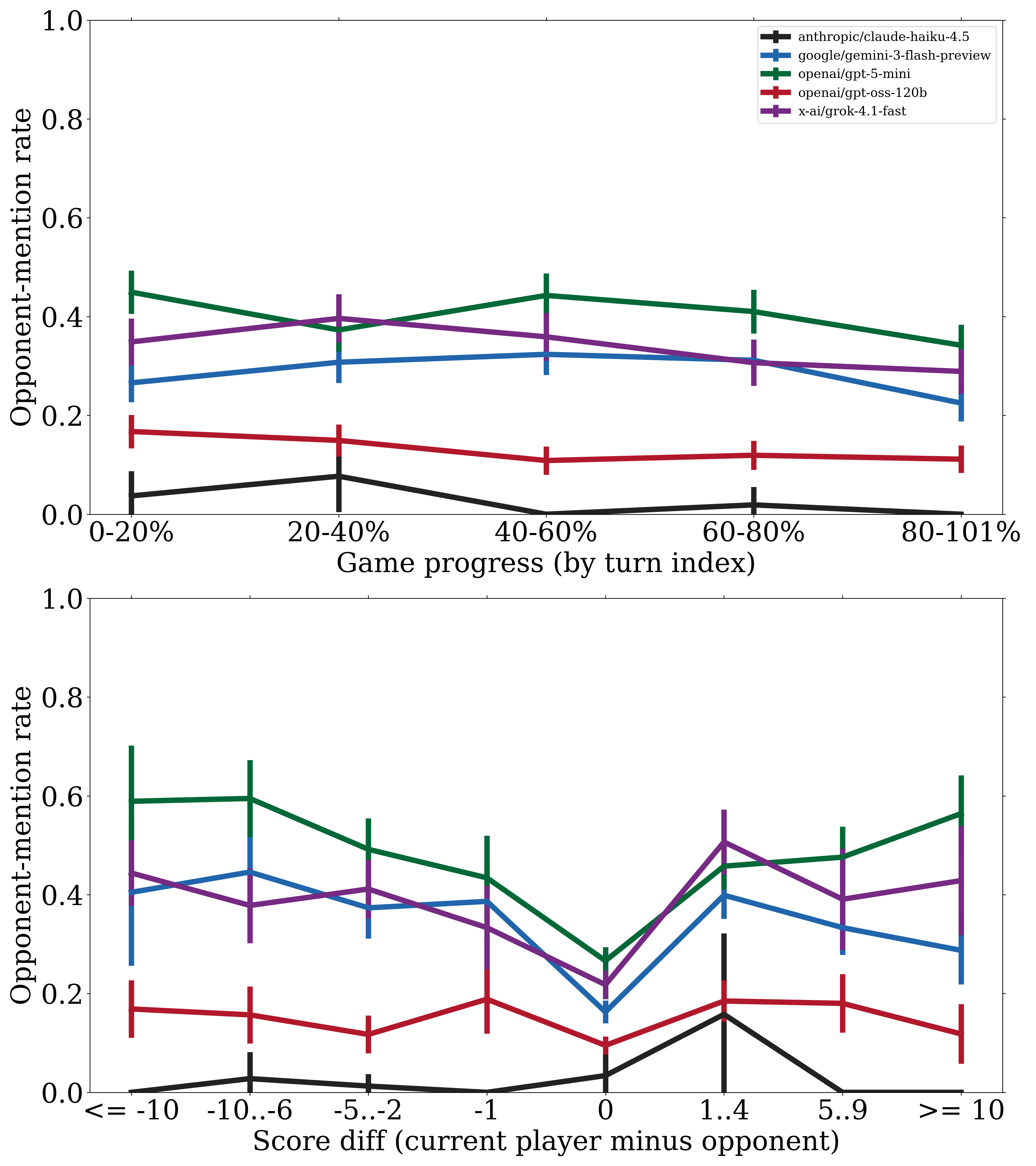
The plots show when models mention opponents (by game progress and score differential). The patterns are slightly different across different models.
What’s Next
- MCTS + neural network to create an “oracle”
- Create deliberately imperfect reward functions (e.g., an LLM judge that overweights “blocking” moves) and fine-tune models on them. Do they learn to game the reward while actual win rate drops? A small-scale test of reward hacking.
- Run with frontier LLMs. These are all the “lite” frontier LLMs. Each move can be ~5000-10000 tokens, 40+ moves a game, many games for a good baseline, so $$ adds up
- Dig into whether we can systematically create a “spite” metric (opponent mention -> action that causes future opponent moves to be less valuable)?
Appendix: Prompt
You are an expert Azul player. Given the full game state, choose the best legal move for the current player.
Rules summary:
- Pick one source (factory or center), take ALL tiles of ONE color.
- Place all taken tiles in exactly one pattern line or the floor.
- A pattern line can only hold one color and cannot exceed its capacity.
- Cannot place color X in a row whose wall already has color X.
- Overflow goes to floor; floor penalties apply.
- Game ends after a row is completed; finish the round and apply bonuses.
State (JSON):
{ ... }
Legal moves (index -> description):
0: take blue from factory 1 to pattern line 2
1: take red from center to floor
...
Respond with JSON: {"action_id": <int>, "rationale": "<short reason>"}
-
Azul ~ A Tool? ↩